
Vivado UltraFast设计方法指南_设计(UG949)
Published:
使用XILINX的设计方法学能够帮助设计者更好地利用资源。特别关注频率,面积,功耗这些指标、
- 注意logic level的概念,指的是两层寄存器之间有几层LUT组合逻辑。
控制信号集
复位
如果需要复位,赛灵思建议代码同步复位。与异步复位相比,同步复位拥有众多优势。
使用复位时,确保该程序语句中的所有寄存器都有复位。
时钟使能
- 如果正确使用,时钟使能能够显著地降低系统功耗,同时对面积或性能的影响极小。
所有寄存器的置位/复位功能的优先级均高于时钟使能,不论是异步置位/复位还是同步置位/复位都是如此。为取得最佳结果,赛灵思建议在同步块中的 if/else 结构中,应一直在时钟使能 (如有必要使用)之前对置位/复位进行编码。优先对时钟使能进行编码会强制复位进入数据路径,并导致产生更多逻辑。 示例:(* DIRECT_ENABLE = “ture” *)
- 将 DIRECT_ENABLE 属性添加到端口/信号,可以使能信号 (en) 连接到寄存器的CE引脚。
了解器件调用
- 三值加法(ternary addition)所使用的资源大致与二值加法相当,因此一次三值加法可以比两次二值加法省一半的资源。
one LUT per 2-bit/3-bit addition is used.
- 利用DSP内部流水线资源
DSP blocks have three levels of pipelining resources inside them. Pipelining properly for logic inferred into the DSP block can greatly improve performance and power.
- 利用移位寄存器
Two SRLs with depths of 16 bits or less can be mapped into a single LUT, and single SRLs up to 32 bits can also be mapped into a single LUT.
- 选通器 For conditional code resulting in standard MUX components:
- A 4-to-1 MUX can be implemented into a single LUT, resulting in one logic level.
- An 8-to-1 MUX can be implemented into two LUTs and a MUXF7 component, still resulting in effectively one logic (LUT) level.
- A 16-to-1 MUX can be implemented into four LUTs and a combination of MUXF7 and MUXF8 resources, still resulting in effectively one logic (LUT) level.
- 对通用逻辑而言,考虑给定寄存器具有唯一的输入数。根据这个数量,就可以估计出可能实现的 LUT 数量和逻辑层数 量。一般来说, 6 个或六个以下输入会产生一个逻辑层。理论上两个逻辑层可以管理多达 36 个输入。但实际上两个逻 辑层最多仅能管理 20 个输入。一般来说如果输入数量越多,逻辑等式越复杂,那么需要的 LUT 和逻辑层就越多。
- For general logic, take into account the number of unique inputs for a given register. From that number, an estimation of LUTs and logic levels can be achieved. In general, 6 inputs or fewer always results in a single logic level. Theoretically, two levels of logic can manage up to 36 inputs. However, for all practical purposes, you should assume that approximately 20 inputs is the maximum that can be managed with two levels of logic. In general, the larger the number of inputs and the more complex the logic equation, the more LUTs and logic levels are required.
调用RAM和ROM
- 隐式调用
- 优势:
- 高度可移植
- 便于阅读和理解
- 自我文档化
- 快速仿真
- 不足:
- 不能访问所有可用的 RAM 配置
- 可能产生不够理想的结果 调用 RAM 时,赛灵思建议使用 Vivado 工具中提供的 HDL 模板。
- 赛灵思可参数化宏 (XPM)
- 优势:
- 可在赛灵思器件系列之间移植
- 快速仿真
- 支持不对称宽度
- 可预测的 QoR
- 不足:
- 仅支持 XPM 选项
- 直接实例化 RAM 原语
- 优势:
- 对实现方案有最高控制权限
- 能访问块的各项功能
- 不足:
- 代码可移植性差
- 功能和用途冗长繁琐,难以理解
- IP目录提供的IP核
- 优势:
- 在使用多个组件时一般能提供更优化的结果
- 设定和配置简单
- 不足:
- 代码可移植性差
- 需要管理内核
实现RAM的性能考虑
选择BRAM还是DRAM——深度意味着地址宽度 一般来说 RAM 要求的深度是首要选择标准。高达 64 位深度的存储器阵列一般实现在 LUTRAM 中,其中深度不超过 32 位的映射为每个 LUT 的 2 位,深度达到 64 位的映射为每个LUT 的 1 位。深度更大的 RAM 根据可用资源和综合工具赋值,也可实现在LUTRAM中。 深度超过 256 位的存储器阵列一般实现在块存储器中。赛灵思 FPGA 器件能够灵活地以多种宽度深度组合映射此类阵列。用户需要熟悉这些配置,才能了解代码中更大规模存储器阵列声明所使用的块 RAM 的数量与结构。
- 使用输出流水寄存器
与块 RAM 寄存器相比,slice 输出寄存器具有更快的时钟输出时序。使两个寄存器的总读取延迟为3。
- 使用输入流水线寄存器 当 RAM 数组很大并映射到许多原语时,它们可以跨越相当大的die晶片区域。这可能导致地址和控制线上的性能问题。考虑在生成这些信号之后和 RAM 之前添加一个额外的寄存器。为了进一步提高时序,稍后在流程中使用phys_opt_design 来复制此寄存器。无逻辑的寄存器的输入将更容易复制。
注意事项
- 避免单端口RAM综合出不必要的(两级)输出寄存器。
- 不能复位RAM但可以对输出寄存器复位。
DSP使用
- DSP 块能够执行多种不同的功能,包括:
- 乘法
- 加法和减法
- 比较器
- 计数器
- 普通逻辑
- 赛灵思器件中的 DSP48 slice 寄存器只包含复位功能,没有置位功能。因此除非必要,应避免围绕乘法器、加法器、计数器或其它可在 DSP48 slice 中实现的逻辑进行置位编码 (在施加信号的情况下,逻辑值等于 1)。
- DSP slice 只支持同步复位操作,应避免异步复位。
SRL使用
- 为在使用 SRL 时获得最佳性能,赛灵思建议把最后一级移位寄存器实现在专用 slice 寄存器中。 slice 寄存器与 SRL 相比,输出相对于时钟时延 (clock-to-out) 更短。这样可以为从移位寄存器逻辑出发的路径提供更大的时序裕量。
- 如果要使用寄存器来达到灵活布局芯片的目的,使用下列属性关闭 SRL 调用:
SHREG_EXTRACT = “no”
初始化全部调用的寄存器、SRL和存储器
除少数情况,比如 one-hot 状态机编码, Vivado 综合工具一般都设定默认值为 0。
- 经配置后 FPGA 器件中所有的同步元件都会从已知值启动,这样做可避免纯粹为初始化目的添加复位功能,让 RTL代码在功能仿真中更贴近实现的设计。
reg register1 = 1’b0; // specifying regsiter1 to start as a zero reg register2 = 1’b1; // specifying register2 to start as a one reg [3:0] register3 = 4’b1011; //specifying INIT value for 4-bit register
- 对隐式调用和实例化,赛灵思都建议用户使用 Vivado Design Suite 语言模板中提供的实例化和语言模板。
提升性能的编码方式
关键路径上的高扇出
- 高扇出网络宜在设计过程早期阶段进行处理。性能要求和路径的结构往往会导致高扇出问题。应尽早检查有大量负载的网络,评估其对总体设计的影响。
使用寄存器复制
- 如果根据时序报告,带有长布线延迟的高扇出网络被报告为关键路径,应考虑复制综合工具上的约束和手动复制寄存器。您往往必须添加额外的综合约束,才能确保手动复制的寄存器不会被综合工具优化掉。
- To preserve the duplicate registers in synthesis, use a
KEEPattribute instead ofDONT_TOUCH. ADONT_TOUCHattribute prevents further optimization during physical optimization later in the implementation flow. - If a LUT1 rather than a register is replicated, it indicates that an attribute or constraint is applied incorrectly.
- Using
MAX_FANOUTattributes on global high fanout signals leads to sub-optimal replication similar to when the global fanout limit is lowered in synthesis. For this reason, Xilinx recommends only usingMAX_FANOUTinside the hierarchies on local signals with medium to low fanout. - 请勿复制寄存器用于同步跨时钟域的信号。
- If the timing reports indicate that high-fanout signals are limiting the design performance,consider replicating the signals using the implementation tool options, such as
opt_design -hier_fanout_limit,place_design, andphys_opt_design. - When replicating registers, consider using a naming convention for the registers, such as
<original_name>_a,<original_name>_b, etc., to make it easier to understand intent of the replication and easier to maintain the RTL code. - 个人认为高性能设计扇出不大于100。100,200,5000是扇出阈值。
采用流水线
- 未采用流水线时,n级组合逻辑时钟速度受下列因素限制:
- 源触发器的时钟到输出时间,即输出相对于时钟时延 (clock-to-out);
- 贯穿n个逻辑级数的逻辑延迟;
- n个组合函数发生器的相关布线;
- 目的地寄存器的建立时间。
- 采用n级流水线后,时钟速度受以下限制:
- 源触发器的输出相对于clock-to-out延迟;
- 贯穿一个逻辑级数的逻辑延迟(同slice布线延时可忽略);
- 一个布线延迟和目的地寄存器的建立时间。
是否需要流水线
- To determine whether a design requires pipelining, identify the frequency of the clocks and the amount of logic distributed across each of the clock groups. You can use the
report_design_analysisTcl command with the-logic_level_distributionoption to determine the logic-level distribution for each of the clock groups. - 要通过添加流水线级来平衡延迟,请将该级添加到控制路径(control path)而不是数据路径(data path)。数据路径包括更宽的总线,这增加了所使用的触发器和寄存器资源的数量。
- 例如,如果您有 128 位数据路径, 2 级寄存器,并且需要 5 个周期的时延,则可以添加 3 级寄存器:3 x 128 = 384 触发器。或者,您可以使用控制逻辑使能数据路径。使用单级位流水线的 5 级,并使能数据路径触发器。
- FPGA 中的最佳 LUT:FF 比为 1:1。具有显着更多 FF 的设计将增加不相关的逻辑打包成片,这将增加布线复杂性并且可以降低 QoR。
深度流水线与SRL
- 当有更深的流水线阶段时,要尽可能地映射到 SRL 中。这种方法保留了器件上的触发器/寄存器。例如, 9 层深的流水线级 (对于 32 的数据宽度)导致每个比特的 9 个触发器/寄存器,使用 32×9 = 288 个触发器。将相同的结构映射到SRL 使用 32 个 SRL。每个 SRL 都连接到 5’b01000 的地址引脚 (A4A3A2A1A0)。
- 复位会影响SRL调用:
- 确保没有用于流水线级的重置。
- 分析是否真的需要重置。
- 在一个触发器上使用复位 (例如,在pip的第一级或最后一级)。
- 考虑流水线宏原语 基于目标架构,如果使用足够的流水线,专用原语 (如块 RAM 和 DSP)可在 500 MHz 以的上的频率范围工作。对于高频设计,赛灵思建议使用这些块中的所有流水线。
自动流水线
- AXI pip 未读
优化功耗的编码方式
门控时钟或数据路径
- 对时钟或数据路径实施门控是当不使用路径结果时用来停止跳变的常用技术。门控时钟能停止所有同步负载;并防止数据路径信号开关和毛刺继续传输。
Power optimization (
power_opt_design) can automatically generate signal gating logic to reduce switching activity. However, you have information about the application, data flow, and dependencies that is not available to the tool, which only you can specify- 当对时钟实施门控或多路复用以最大限度降低活跃度或时钟树使用量时,应采用专用时钟缓存的时钟使能端口。插入LUT 或使用其它关闭时钟信号的方法在功耗和时序上效率不高。
不要使用过度精细的时钟门控。每个门控时钟应能影响大量同步元件。
- 当不需要优先编码器时使用 Case 块
- 当不需要优先编码器时,应使用 case 块,而不是如果-则-否则 (if-then-else) 块或三元运算符。
- 低效率编码实例
if (reg1) val = reg_in1; else if (reg2) val = reg_in2; else if (reg3) val = reg_in3; else val = reg_in4;
- 正确编码实例
(\* parallel_case \*) casex ({reg1, reg2, reg3}) 1xx: val = reg_in1 ; 01x: val = reg_in2 ; 001: val = reg_in3 ; default: val = reg_in4 ; endcase
块RAM的性能/功耗权衡
- 对于 UltraScale 和更高版本的器件,综合可以限制使用
CASCADE_HEIGHT属性进行性能/功耗折衷的块RAM的级联。 - 例如,对于32个BRAM的级联:
- CASCADE_HEIGHT=1,所有块 RAM 一直处于使能状态 (对于每次读或写)而且消耗更多功耗。(高功耗)
- CASCADE_HEIGHT=32,由于每次 (从每个单元中)只选择一个块 RAM,因此动态功耗几乎减半。(最低功耗)
- CASCADE_HEIGHT=4,因为一次选择 8 个块 RAM,所以动态功率贡献比高性能结构好,但不如低功率结构好。与低功率结构相比,该结构的优点在于,在级联路径中仅使用 4 个块 RAM,这与在低功率结构的关键路径中的 32 个块 RAM 相比对目标频率有影响。(权衡)
- 可以在 RTL 中使用
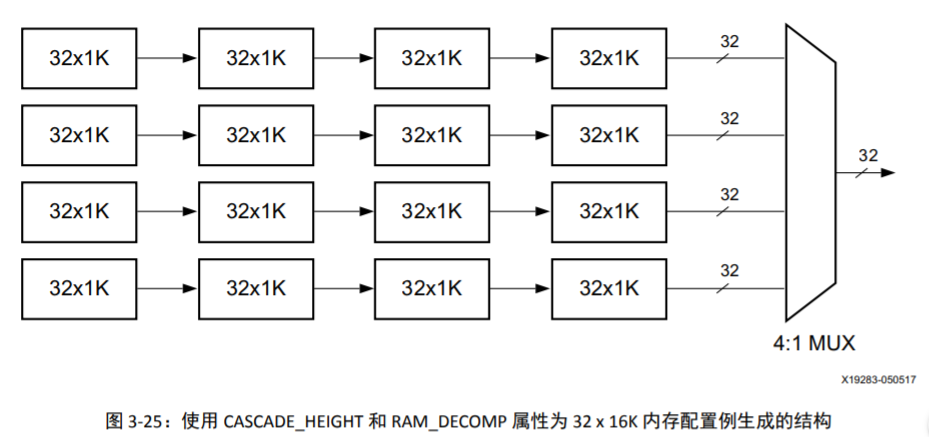
RAM_DECOMP综合属性,通过提升内存组成来降低功耗。 - 例如,对一个32 x 16K内存配置
- 如果您应用下列属性:
ram_decomp = "power" cascade_height = 4
- 隐式调用16个RAMB36E2且内存按下列方式进行分解:
- 基本原语 32 x 1K。
- 级联 4 个块 RAM,以创建 32 x 4K 配置。
- 4 个并行结构可创建一个 16K 深内存。
- 复用输出生成输出数据。
运行RTL DRC
* DRC 检查可在 Flow Navigator 中通过“RTL Analysis > Report Methodology”执行,也可根据 Tcl 命令提示符通过执行report_methodology来实现。您可单击 Flow Navigator下的“Open Elaborated Design”便可打开细化视图并进行检查。
编码指南
- 每个 FPGA 架构都为时钟提供有专用资源。掌握 FPGA 架构中的时钟资源,使您能够规划好自己的时钟,从而实现时钟资源的最佳利用。大多数设计无需您了解这些细节。但如果您能够控制布局,同时对每个时钟域上的扇出有良好的思路,就可以根据下面的时钟详情,研究出多种备选方案。如果您决定使用任何时钟资源,就需要具体地实例化相应的时钟元件。
7系列器件时钟 Virtex®-7为例
- 器件内含称为BUFG的全局时钟缓存。
- 时钟数量
- 设计性能
- 功耗需求低
- 其它时钟特性,比如:
- 时钟门控
- 多路复用
- 时钟分频
- 其它时钟控制
- BUFG 可通过综合功能调用得到,同时限制条件极少,适用于大多数普通时钟。
全局时钟资源
这部分将探讨下列全局时钟资源:
- BUFG 全局时钟缓存 (BUFG) 元件一般供时钟使用。这种全局时钟缓存带有附加功能。这些附加功能可通过手动干预设计 代码或综合加以利用。
- BUFGCE 在使用 BUFGCE 原语的情况下,无需使用任何其它逻辑或资源,就能够访问同步无毛刺时钟使能 (门控)功能。BUFGCE 可让时钟停止一段时间,或用于创建更低偏差、更低功耗的时钟分频信号,比如从更高频率的基时钟创建 ½ 或 ¼ 频时钟,特别适用于在电路工作的不同时间需要不同频率时钟的情况。
- BUFGMUX BUFGMUX 可用于安全地修改时钟,实现从一个时钟源到另一个时钟源无毛刺切换,同时不会造成其它时序风险。在需要根据时间条件或工作条件的情况下, BUFGMUX 可使用两个截然不同的时钟频率。
BUFGCTRL BUFGCRTL 能够访问全局时钟网络的全部功能,以便于异步控制时钟来适应更加复杂的时钟条件,比如时钟丢失或停止时钟切换电路等。
- 时钟管理片 (CMT) 包含
- PLL 锁相环
- 混合模式时钟管理器(MMCM)
区域时钟资源
除全局时钟资源之外,还有区域时钟资源:
- 水平时钟域缓存 (BUFH、 BUFHCE)
在独立使用时,所有连接到 BUFH 的负载必须处于相同的时钟域中。这样能良好地满足超高速、更加精细粒度(更少负载数量)的时钟需求。BUFHCH 可用于实现特定时钟域中的中等粒度时钟门控。用户必须确保由 BUFH 驱动的资源不会超出时钟域中的可用资源,且不存在其它冲突。
- 区域缓存 (BUFR)
- 在 Virtex-7 器件中,BUFR 只能驱动其所在的时钟域。这使得这种缓存更适用于较小型的时钟网络。
- BUFR 的性能略低于 BUFG 和 BUFH,赛灵思不建议将其用于超高速时钟。
非常适用于许多中低速时钟的需求。附加的内置时钟分频功能也使之适用于由高速 I/O 接口时钟等外部时钟源驱动的分频时钟网络。 BUFR无需占用全局走线,并能替代 BUFH 的使用。
- I/O 时钟缓存 (BUFIO)
- I/O 时钟缓存 (BUFIO) 只用于采集 I/O 数据到输入逻辑,并在器件上为输出逻辑提供输出时钟。 BUFIO 一般用于:
- 在 bank 中采集高速源同步数据
- 在器件中把数据降低到更可控的速度 (结合 BUFR、 ISERDES 或 OSERDES 逻辑使用)。
- 多区域时钟缓存 (BUFMR)
- 多区域时钟缓存 (BUFMR) 允许使用单个时钟引脚 (MRCC) 驱动位于自身 bank 中的 BUFIO 和 BUFR,以及其上下的I/O bank (如果存在)。
时钟结构设计
调用
- 无需用户干预,Vivado 综合工具就可以自动为所有时钟结构设定全局缓存 (BUFG),直到架构允许的最大数量(除非用综合工具另行设定或加以控制)。如前文所述, BUFG 能够提供满足大多数时钟需求的、受控良好的低偏差网络。除非器件上的 BUFG 数量或功能无法满足设计的时钟要求,无需另行干预。
- 但是如果对时钟结构施加额外控制,在抖动、偏差、布局、功耗、性能或其它方面可能会获得更优异的特性。
综合约束和属性
- 控制时钟资源的简单方法是使用
CLOCK_BUFFER_TYPE综合约束或属性。综合约束可以用于: - 防止 BUFG 调用。
- 用替代性时钟结构取代 BUFG。
- 设定某种以其它方式无法实现的时钟缓存。
- 使用综合约束,无需对代码进行任何修改,就可以实现此类控制。属性可布局在任意下列位置之一:
- 直接布局在 HDL 代码中,这样属性就可以一直存在于代码中
- 作为 XDC 文件中的约束,这样无需修改源 HDL 代码就能实现此类控制。
IP 的使用
- 某些 IP 对创建时钟结构有帮助。 Clocking Wizard 和 I/O Wizard 专用于协助时钟资源和结构的选择和创建,包括:
- BUFG
- BUFGCE
- BUFGCE_DIV (UltraScale 器件)
- BUFGCTRL
- BUFIO (7 系列器件)
- BUFR (7 系列器件)
- 时钟修改块,如:
- 混合模式时钟管理器 (MMCM)
- 锁相环 (PLL) 组件
- 存储器接口生成器 (MIG)、PCIe 或收发器向导等更复杂的 IP 也可囊括时钟结构,当作总体 IP 的一部分。如果适当加以考虑,这也可以提供额外的时钟资源。但如果不加考虑,可能会限制设计其余部分的某些时钟选项。
- 赛灵思强烈建议对任何实例化的 IP 均应良好掌握其时钟的要求、功能和资源,并尽量在设计中的其余部分加以运用。
控制时钟的相位、频率、占空比和抖动
使用时钟修改块 (MMCM 和 PLL)
用户可使用 MMCM 或 PLL 修改输入时钟的总体特性。MMCM 最常用于消除时钟的插入延迟(将时钟与输入系统同步 数据在相位上对齐),例如:
- 创建更加严格的相位控制。
- 滤除时钟中的抖动。
- 修改时钟频率。
- 纠正或更改时钟占空比 为正确使用 MMCM 或 PLL,必须协调多项属性,以确保 MMCM 在规范范围内工作,能够在输出端提供所需的时钟特 性。为此,赛灵思强烈建议使用 Clocking Wizard 来正确配置这一资源。
在时钟上使用 IDELAY 控制相位
对于 7 系列器件来说,如果只需要稍许调整相位,可以使用 IDELAY 或 ODELAY (而非 MMCM 或 PLL)添加额外的延迟。这样可以增大时钟相对于任何相关数据的相位偏移。在使用 UltraScale 器件时,在输入时钟源上您不可使用IDELAY。因此,除非需要相位操纵器,赛灵思建议使用 MMCM。
使用门控时钟
赛灵思器件内置专用时钟网络,可提供高扇出低偏差时钟资源。如果在 HDL 代码中包括精细粒度时钟门控技术,则会干扰此功能及防止专用时钟资源的有效使用。因此,在将 HDL 写入器件时,赛灵思不建议把时钟门控结构编码在时钟路径上。与此相反,出于功能或功耗考虑而停止设计的某些部分,应使用通过编码调用时钟使能的方法来控制时钟。
将时钟门控转换为时钟使能
如果编码中已经含有时钟门控结构,或是另有技术要求这样编码,赛灵思建议使用综合工具把已经布局在时钟路径上的门控重新映射到数据路径上的时钟使能。这样做可以更理想地映射到时钟资源,并简化与进/出门控时钟域的数据有关的电路时序分析。例如,利用 -gated_clock_conversion auto 选项与 Vivado 综合使用,以尝试自动转换为寄存器时钟使能逻辑。对于复杂的门控时钟结构,使用 RTL 代码中的 GATED_CLOCK 属性来指导 Vivado 综合。 门控时钟缓冲器 当时钟网络的较大部分可以关闭一段时间时,您可以使用 BUFGCE 或 BUFGCTRL 启用或禁用时钟网络。此外,在定向UltraScale 器件时,可以门控 BUFGCE_DIV 和 BUFG_GT。对于 7 系列器件,还可以使用 BUFHCE、 BUFR 和 BUFMRCE来门控时钟。
避免本地时钟
创建输出时钟
跨时钟域 (CDC)
跨时钟域 (CDC) 电路在设计中直接影响设计的可靠性。您可以设计自己的电路,但 Vivado Design Suite 必须识别电路,并且必须正确应用 ASYNC_REG 属性。赛灵思提供 XPM 以确保正确的电路设计,包括:
- 在
place_design中驱动特定功能,减少同步电路上的平均故障间隔时间 (MTBF)。 - 确保通过
report_synchronizer_mtbf进行识别。 - 避免
report_cdc错误和警告,这通常在迭代较长时在设计周期中显示。 当在两个异步时钟之间交叉时或者当试图通过添加假路径约束来放松两个同步时钟之间的时序时,需要 CDC 电路。使用 XPM 时,可以选择单个位或多位总线在域之间交错。
充分利用 IP 核
规划 IP 要求
对任何新工程而言,规划 IP 要求都是最重要的环节之一。
- 根据所需功能以及其它设计目的评估赛灵思或其它第三方合作伙伴提供的 IP 选项,例如:
- 与现可用的 IP 核相比,定制逻辑是否更好?
- 用业界标准格式封装定制设计,便于在多个工程中重复使用是否有意义?
- 考虑需要使用的接口,比如存储器接口、网络接口和外设接口。 为确保这些工具进程正确地处理 IP 专用约束,为项目添加 .xci 或 .xcix IP 源文件。在使用 IP 工作时,勿将IP生成的输出 DCP 文件作为项目源。
AMBA AXI
赛灵思已对符合开放式 ABMA® 4 AXI4 互联协议的 IP 接口进行了标准化。这种标准化能够简化赛灵思和第三方提供商 提供的 IP 的集成工作并最大化系统性能。为有效地映射到自己的 FPGA 器件架构中,赛灵思与 ARM 共同制定了 AXI4、 AXI4-Lite 和 AXI4-Stream 规范。
- AXI 专为高性能、高时钟频率系统设计制定,适用于高速互联。
- AXI4-Lite 是 AXI4 的精简版,主要用于接入控制寄存器和状态寄存器。
- AXI-Stream 用于从主设备到从设备的单向数据流。典型应用包括 DSP、视频和通信。
小结
关于时钟、综合、实现仍有必要深入学习。此外Tcl很有用。
不要时钟门控,要用数据路径上的时钟使能
堆叠硅片互联 (SSI) 技术器件,即7 系列器件 超级逻辑区域 (SLR) 支持时钟功能的 I/O (CCIO) 时钟管理模块 (CMT)